
4 minute read
Replay: In the first of a three-part series, Phil Rhodes explains how artifical intelligence works, a technology that will affect us all ever increasingly in the coming years.
Some of the most forward-looking bits of speculation about AI is that it could, in theory, turn vague ideas into finished artistic works without much human intervention. Computer-composed music has existed for some time, though there's an important distinction between a computer algorithm and something we can realistically call an AI. And yes, we're a very, very long way from having a computer spit out a feature film that's recognisable as such, let alone something of any quality, based solely on a pitch document. Still, AI does, theoretically, relax some of the handcuffs of information theory that implies we can't have an automatic photograph sharpener.
Early artificial intelligence was usually not creative. Work with neural networks, particularly in the late 80s and early 90s, was mainly intended to be used to classify things. The standard example is handwriting recognition in which we're often interested to decide which of seventy or eighty characters (including upper and lower case, numerals, punctuation, etc) we're looking at. To this day, that's a very common application of the technology. The point is, however, that it isn't inherently creative — most of the neural networks that have existed can analyse the contents of a picture, but they can't necessarily draw a new picture.
That's what we're asking for — on a vastly grander scale, of course — when we conjecture about having an AI produce a movie. The technique used to have modern AIs create new designs is often the generative adversarial network, which is what we originally intended to cover in this piece, but a basic understanding of it sort of requires that we're more or less familiar with neural networks, to begin with.
At the 1980s level we mentioned earlier, a neural network is disarmingly simple and does indeed work very much like the neurons in a brain. The idea is that there's a bunch of input neurons, each of which can be activated to a varying degree. Sometimes these might represent pixels in an image, in which case we'd have 35 for a 5-by-7 pixel image. On the other side of the network are some output neurons, perhaps 26 if we're trying to identify uppercase letters. Let's assume we're identifying an L.
![]()
Between those two we have one or more layers of “hidden” neurons. The neurons in each layer are connected to those in the previous and following layers and it's the setup of those connections which make it do something useful.
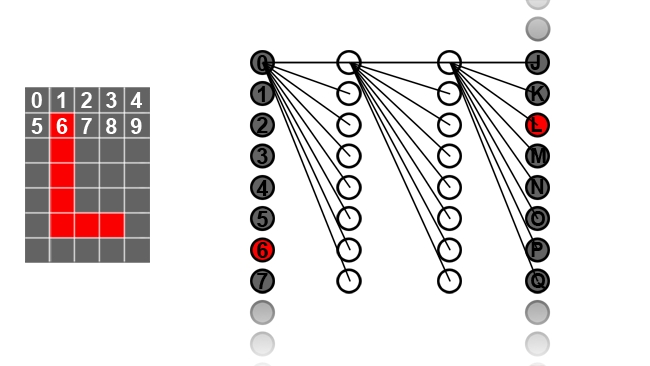
The image of the letter L will typically activate some input neurons more than others and it'll do that in a way that's different to the letter O. That's just basic pattern recognition, though, and we know that trying to match a handwritten character to an example we've got on file isn't a very reliable way of recognising handwriting. A neural network, on the other hand, tries to solve the problem in many layers, breaking the task down into manageable chunks. For instance, a human being might describe the process of recognising an uppercase letter L as looking for a vertical and horizontal line. An O, conversely, is a circle, and so on.
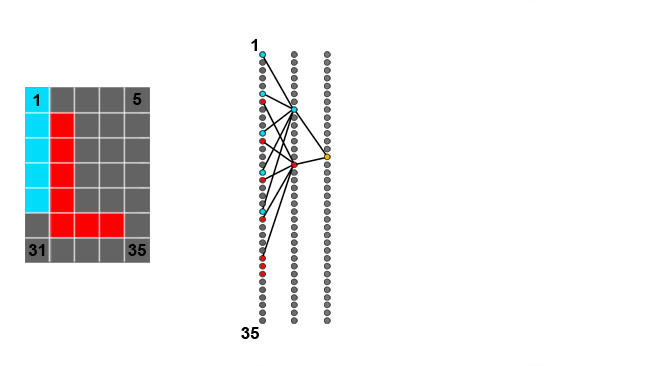
To recognise a vertical line, we might place a neuron in the first hidden layer which we call the vertical line neuron. All the input neurons are connected to it. We can weigh the amount of importance any of the connections have, so connections coming from neurons representing the vertical line pixels have more influence than neurons representing other pixels. To find vertical lines, we apply a big positive weight to connections from input neurons that would be activated if a vertical line were to appear in the image, and a negative weight to others. The result is a neuron that's activated whenever there's a vertical line in the image.
![]()
OK, so the line might be in various positions. Theoretically, we could have dozens of vertical-line neurons in the first hidden layer intended to detect vertical lines at various positions in the image. We could add another layer of neurons and connect all the vertical-line neurons in the first hidden layer to a single one in a second hidden layer. We just show two vertical lines being detected here, but repeat this often enough and the single vertical-line neuron would then be active whenever there's a vertical line anywhere in the image.
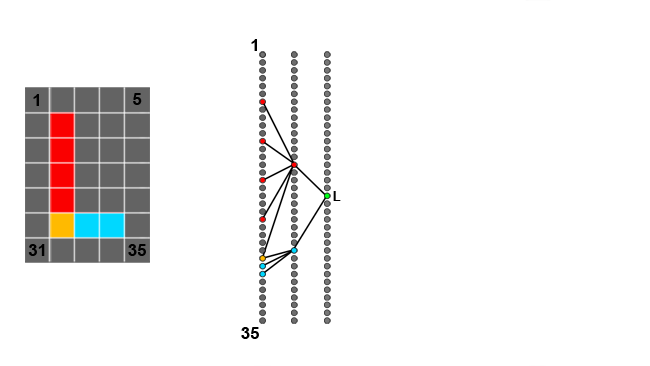
A real network might add neurons configured to detect other things, horizontal lines and curves, for instance — probably dozens of them. Ultimately, we end up with two or three layers of neurons which will detect the various components of uppercase letters. All of the neurons in each layer are connected to all the neurons in the following layer, with the influence of the connection weighted such that each neuron reacts to some useful pattern and then to combinations of patterns. As we add more and more layers, we become capable of reacting usefully to increasingly complex combinations of patterns.
Let's see if we can detect a letter with this. Let's find the neurons in the hidden layers which detect a vertical line, and those which detect a horizontal line. Let's connect those to the output neuron for the letter L — we can also connect up all the other neurons, such as those which detect circles, and give them a negative weight, so that we can ensure that situations where we have only one horizontal line and one vertical line will be interpreted as an L. Okay, if we put in enough connections so we can detect lines anywhere in the image, we're now going to confuse L and T, both of which have horizontal and vertical lines, but this is very, very roughly the principle.
In practice, real handwriting-recognition networks don't really work like that. A working handwriting-recognition network has many layers which will detect various patterns in the input data. These will have some sort of relevance to the character they represent, but it isn't as tidy as detecting lines and circles. The problem with neural networks is that they tend to contain vast numbers of neurons and vast numbers of connections between them. Each of those connections needs a weight, which is a huge collection of numbers to represent how the network is configured — more than we can realistically set up by hand. This is where training the network comes in, which is a subject for another day.
Header image courtesy of Shutterstock.
Tags: Technology

RedShark 2020 @ All rights reserved.

Comments