
4 minute read
In the second part of his in-depth series on artificial intelligence, Phil Rhodes continues by looking at the training of the neural network.
Last time, we looked at how neural networks roughly operate and how layers of neurons are connected together in order to recognise patterns in the data we give it. To get a better idea of how this might work, we imagined the pixels in an image as our input neurons, each with an activation level. The input neurons might be connected to the next layer with the weights set up so that a bright column of pixels activated a single neuron that represents a vertical line. Do that for a large enough number of different shapes, combining them through a large enough number of layers to create more complicated shapes, and we might end up with a neural network capable of identifying handwritten letters.
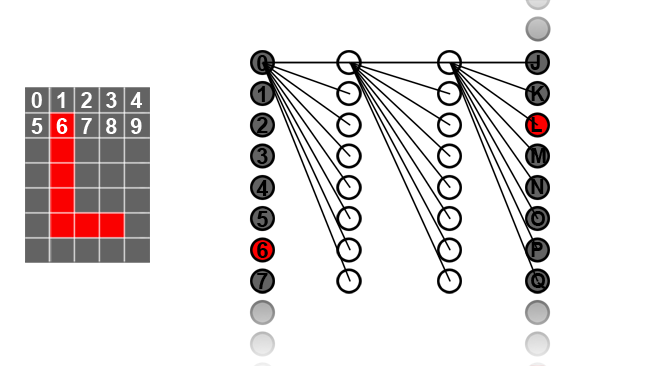
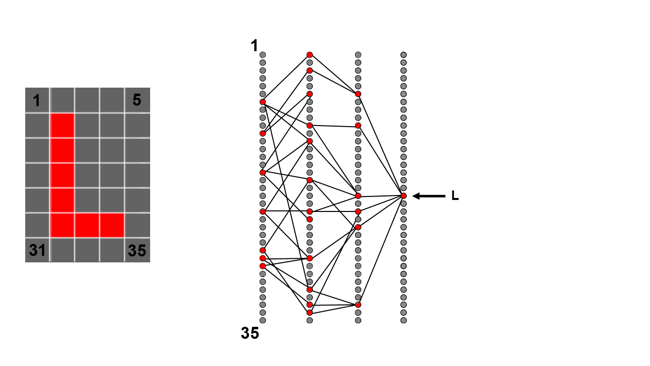
There are a couple of problems with this simple description, though. The main issue is simply in how we set up the network. If we have an input image of, say, five by seven pixels, which is enough to display a basic alphabet, there are 35 pixels and therefore 35 input neurons. Never mind that real-world numbers are much larger because an image big enough to hold a reasonable depiction of a handwritten character tends to have a much higher resolution than that. Still, if the input layer has 35 neurons, even if the first hidden layer only had five (which wouldn't be enough to be useful) there's still 35 × 5 = 175 connections between the input and the first hidden layers. Each of those connections needs a weighting factor, so that's a lot of numbers to set up, especially on the much larger networks required to do real-world jobs on higher resolution images.

Even on simple tasks, the number of interconnections rapidly becomes massively larger than we could reasonably set up by hand. Happily, a neural network can be trained in much the same way as a person. In our example, we're trying to identify handwritten characters, so we need a big stock of images of handwritten characters, each labelled with a reliable indication as to what character it's supposed to represent. The trick is that we set up our network by putting random values on the weights for each interconnection between neurons, and then train it using a technique called backward propagation of errors or backpropagation.
When we put some image data on the input neurons of a network with random weighting, the output will be garbage. We have (say) 26 output neurons and to identify a character reliably, we want one of them to be fully activated and the rest not activated at all. In reality, we'll end up with one noticeably more activated than the others, which is a measure of how confident the network is in its identification of the character. Still, it's likely that, with a random setup, the output layer will be activated randomly.
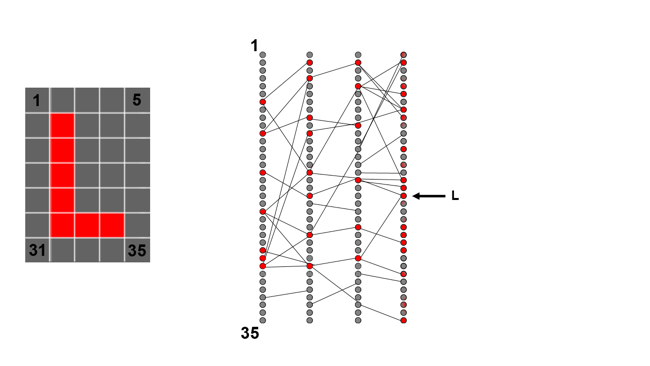
The trick is that when we're training, we know which letter is actually shown in the input image we're using, so we know which output neuron we actually want to be activated. We, therefore, know that we need to increase its activation level and decrease the activation level of other, incorrect neurons. Note that these figures show a lot fewer connections between neurons than there would usually be, for simplicity.
In order to do that, we return to the neurons in the hidden layer immediately before the output and tweak the weights of the connections between them and the output. Assuming our input image is an L, with random weights on all the connections, we might find that various output neurons other than L are strongly activated, which is wrong. So, we'd go back to all the previous layer neurons which are strongly activated and tweak down the weighting with which they're connected to the incorrect output neurons.
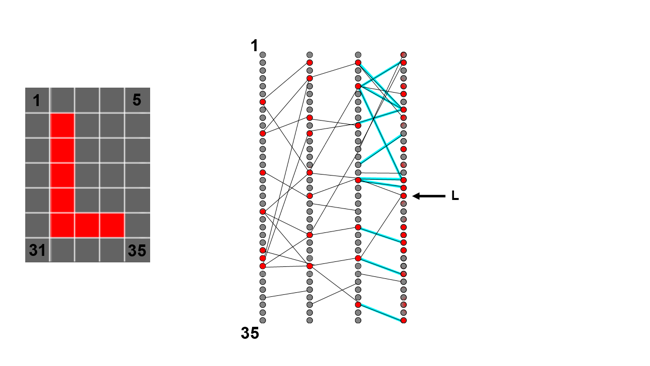
Then, depending on how many layers we have, we can keep moving backwards through the network, reducing the weighting of connections which give us outputs we don't like and increasing the weighting of connections which give us outputs we do.
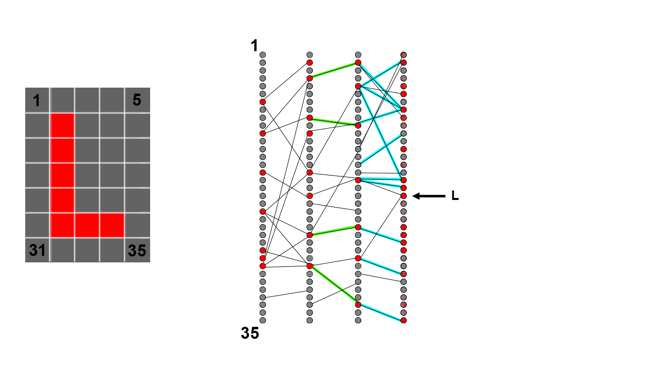
The amount by which we tweak is very small and we have to do this repeatedly, with a large number of test inputs representing different characters, before the network starts to become able to recognise things reliably. The result is that each layer of neurons is set up to recognise something that helps the right output neuron light up for a given input image.
What those inner layers of neurons are actually doing, on the other hand, is not something that we directly control. Neural networks can sometimes appear to be something of a black box, with inner workings that we don't really understand. For this reason, AI safety is a very real concern: we really don't know what these things are thinking, which in the long term could have real-world safety concerns.
For now, it's certainly true that real-world character recognition neural networks don't tend to work by identifying nice clean shapes. We can tell what sort of shape a neuron in the first hidden layer is dedicated to identifying by taking all its connections to the input layer's neurons and viewing the weights as an image. That shows us the pixels the neuron cares about; which pixels it's taking notice of, and therefore what sort of shape it's trying to identify. In real-world neural networks, the result of that tends to be a noisy, splotchy mess, not a nice clean shape, but crucially it is a splotchy mess that helps the network come up with the right identification for handwritten characters. Go further into the hidden layers, however, and we're looking at the way in which the network combines those noisy, splotchy messes in order to understand things about handwritten characters. The innards of a neural network can be something of a black box operation.
Regardless, all of this tends to yield much better results on things like character recognition than other approaches. The thing is, we started off this series talking about having AI creating films and so far all we've talked about is classifiers — AI which can decide which character something is. These AI systems are not creative. In order to get creative, we can use something called a generative adversarial network, which will be our topic next time.
Header images courtesy of Shutterstock.
Tags: Production

RedShark 2020 @ All rights reserved.

Comments