
5 minute read
 Gone are the days of one format to rule them all. Now we have all sorts of choices regarding colour space, compression, and gamma. What does all the jargon mean?
Gone are the days of one format to rule them all. Now we have all sorts of choices regarding colour space, compression, and gamma. What does all the jargon mean?
Years ago, the question “How are we shooting this?” could be answered with a phrase such as “On digibeta.” Even then, though, we started to encounter terms like “hypergamma”, “Rec. 709” and “compression.” Since then, things have become increasingly complicated, to the point where we regularly need a quick reference guide.
This is such a thing, which will quickly bring people up to speed on the most common terminology. Most full-time camera technicians won't find anything new here, but perhaps it'll be a useful cheat sheet for less technical people who sometimes find themselves bouncing off the jargon.
Codec, colour space and subsampling are not interchangeable terms.
All of these terms have an effect on image quality, but they're not interchangeable. Happily, they're not very complicated either, at least not at the level required to have a sensible conversation about which one to choose.
These things are codecs.
The word codec is a portmanteau of “encoder” and “decoder,” the two essential parts of a video compression system. The camera encodes the picture. Anything which plays the picture back (including the camera, sometimes) decodes it. It's (almost always) the job of the codec to discard some of the picture data in such a way that the loss isn't very noticeable, so it's easier to store. The mathematics behind this is slightly complicated.

Codecs are not bitrates. The same codec could be used at a high bitrate suitable for high-end production or allowing more noticeable degradation in return for smaller files.
Codecs are not filetypes, such as the familiar Quicktime file. Quicktime files, as well as MXF, AVI and many other file types, can contain video which uses many different codecs.
Codecs are not equal to a colour space (see below.) Most codecs don't care what colour space they're encoding.
These things describe colour encoding.
Most people are aware that colour pictures are made up of three layers, most obviously red, green and blue (RGB). In an RGB image, three numbers are stored for every pixel. This ensures high quality, but it's slightly wasteful. Colour and brightness are combined in these three numbers. Since the human eye sees brightness with greater sharpness than it sees colour, it would be nice if we could store the colour at a lower resolution than the brightness to save data space without losing visible quality.
To do this, an RGB image can be mathematically converted into a component image – often (though technically slightly inaccurately) called YUV or (more accurately) YCRCB. In this encoding, the Y channel represents brightness, while the U and V channels represent the colour information. This allows the colour to be stored at a lower resolution, saving data space. We'll talk about that a bit more below.
Colour encoding is not the same as a codec. Many codecs can store material which uses either RGB or YUV colour encoding. Colour encoding is also not a colour space (see below); different shades of red, green and blue yield different results, but the method of encoding is the same.
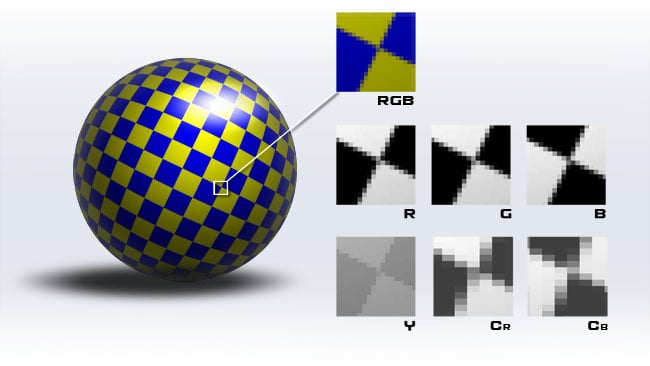
These terms describe colour subsampling, which describes the way in which colour information is sent at a lower resolution to brightness.
This is a technique which reduces the amount of data required to store an image. It's performed as a separate task – before an image is sent to a codec. It uses the fact that component colour encoding (see above) separates brightness information from colour information and stores the colour information at a lower resolution.
The numbers used to describe this are ratios. The common 4:2:2 ratio expresses the fact that for every four Y values, two U and two V values are stored, or, to put it another way, the horizontal resolution of the U and V channels are halved. 4:2:0 is a little odd – it seems to imply that no V-channel information is sent at all, but it's a shorthand for the idea that U and V are halved in resolution both horizontally and vertically. From this, we can probably guess that 4:4:4 images are stored without any subsampling. This is good if we're doing green screen work.
RGB images are intrinsically 4:4:4, but YUV images can be anything. Most codecs can store video streams which use any one of these schemes.
It's (very nearly) possible to derive 4:4:4 HD material from 4:2:2 or 4:2:0 UHD or 4K material. For information on this idea, including more on colour subsampling, see here.
These terms describe gamma encoding, which controls the range of brightness a system can handle.

This refers to the way the brightness of a pixel in the image is stored as a number. It's more efficient to store brightness non-linearly. This means that, if we double the amount of light, the digital number stored in the file doesn't necessarily double. This works because our eyes don't respond like that to increases in brightness either. The result is that the camera system can store a wider range of light levels, from dark shadows to bright highlights.

There's some debate as to what’s the best way to do this and many camera companies have come up with their own proprietary approach. This is not ideal because if two pieces of equipment aren't set to use the same gamma curve, the picture will look too bright, dark, contrasty, or flat.
Codecs, colour encoding and colour subsampling are (largely) irrelevant to gamma encoding. A codec, for instance, can encode any picture we throw at it. The codec doesn't care what the brightness levels represent. That said, the recording must be high quality in general terms so that changes to the brightness meant to make the scene look normal don't reveal compression artefacts.
These terms refer (in part) to colour spaces or colour gamuts, which describe the range of colours a system can reproduce. The notation comes from ITU-R Recommendation BT.709, a standards document created by the Independent Telecommunications Union.
Most of us are familiar with the idea of a colour image being made up of red, green and blue channels. A colour space defines how much red, how much green and how much blue are to be used. If we want to create a really deep blue, we might switch the green and red channels off, and turn the blue channel on to full power. We can't have a deeper blue unless we change the blue we're using.
![]()
Practically, Rec. 709 is associated with conventional HD television. It is notorious for specifying a particularly pale green for its green channel, so it can't represent some teal and turquoise colours. Conversely, Rec. 2020 specifies colours which are as saturated as human vision can handle. This means it is theoretically capable of describing a very wide range of colours, although it is effectively impossible to make a real display that can actually show all of the colours Rec. 2020 can describe.
One small complication is that the documents for Rec. 709 and Rec. 2020 also describe gamma encoding (see above). Conversely, SGamut3 is one example of a proprietary colour space. It doesn't describe gamma encoding and would usually be used alongside Sony's SLog3.
That concludes our jargon-buster for the ways in which we record from modern cameras. Yes, it's complicated – more complicated than it should be, really, if the standardisation procedure was all it could and should be.
Tags: Production

RedShark 2020 @ All rights reserved.

Comments