3 minute read

 Big advance in Speech Animation
Big advance in Speech Animation
UK company Speech Graphics is gunning for the top-spot in lip-sync technology: mark their words. RedShark contributor David Valjalo reports
How does the adage go? Poorly synced virtual lips sink narrative ships. Well, something like that. The fact is, to create unforgettable characters in the modern landscape of computer generated animation they need to be believable. One of the key tools in the war on audience disbelief, keeping them invested in your world, is to make sure they believe the words being spoken belong to the speaker, whether it's a Lorax or a layman.
Enter Speech Graphics, which recently appointed one Colin MacDonald as chairman. A game industry veteran and currently the commissioning editor for games at UK broadcasting powerhouse Channel 4, MacDonald is clear about the bold, raw ambition of the studio: "We’re aiming to be the standard facial animation solution for the AAA games [and] essentially anywhere realistic speech-synchronised facial animation is required", he tells me. A bold ambition for a studio set up just three years ago, but with decades of experience in the field across the team - not least MacDonald's time overseeing videogame developer Realtime Worlds - it's certainly not impossible and the technology is striking (see the video demonstration below along with MacDonald's in-depth explanation of how it all works).
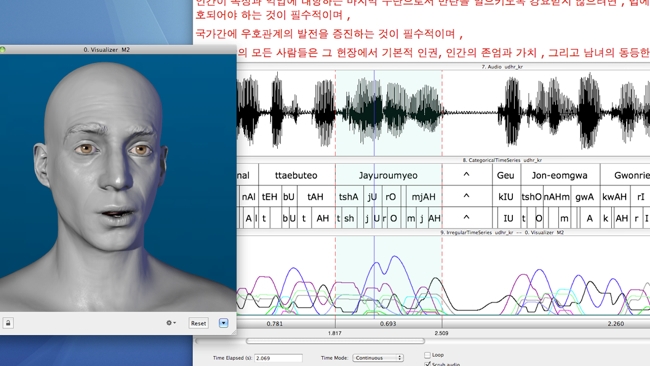
The Science Bit - Colin MacDonald on the tech behind the teeth
Speech Graphics’ core technology involves advances in two main areas: specialised acoustic algorithms for extracting key information from the speech signal, and a revolutionary muscle-dynamic model that predicts how human facial and tongue muscles move to produce speech sounds. The output is high-fidelity lip sync over hours of speech. Moreover, as the muscle-dynamic model is based on universal physical principles, it works across all languages, which is a huge advantage when it comes to localisation. The Speech Graphics solution conveys not just speech but also emotional content, which is captured from the audio through a proprietary analysis. The system matches the dynamics of facial movements to the dynamics of the speaker’s voice, so that the emotional content of the speech is reflected in the face. Going even further, the animation can also be driven by text, using a third-party Text- to-Speech system to drive the same procedural model to output-synchronised facial animation.
Though the bulk of the studio's workload is currently taken up with a raft of triple-A videogame projects, the scope for applying Speech Graphics' technology is far wider than that and the studio has already applied it to a language instruction program due for official reveal in May. There's also application in motion picture CGI film to consider: "Film studios exercise precise frame-by-frame control over animation and have much lower frame counts and different cost ratios than video games but we have seen interest from several movie studios for use of the technology as first-pass and previz animation in film.TV animation on the other hand has higher volume and shorter delivery cycles which make Speech Graphics an attractive solution."
But what about the competition? Videogames, in particular, have been accelerating towards higher and higher fidelity motion capture in the past decade, with titles like Naughty Dog's Uncharted series and the recent blockbuster from Irrational Games, Bioshock Infinite, making leaps and bounds towards a new benchmark in motion capture for games.
"Rather than competing with motion capture studios," MacDonald explains, "we've formed several motion capture partnerships to provide a complementary solution. Motion capture is appropriate for body animation and for capturing broad emotional expressions, but speech is notoriously difficult to capture due to occlusions of the lips and tongue, the deformability of the mouth, and the subtleness and speed of speech movement. Speech Graphics’ procedural audio-driven technology paired with optical or video-based capture offers a complete performance-driven solution."
Lip-syncing with virtual character models isn't anything new, of course, with audio-driven lip sync solutions using far less sophisticated algorithms than Speech Graphics dating back to the ancient early 90s. "With current polygon counts and character realism these crude methods are increasingly out of place," affirms MacDonald. "Speech Graphics is different because they have approached the problem as a speech technology problem and have brought that essential expertise to computer graphics."
There's no denying Speech Graphics' quality today, but what about the future? Sony has already unveiled its plans for the next generation of home entertainment hardware and Microsoft is prepping its own show-and-tell next month. As game platforms change, so too do the quality and fidelity of the games they host. The question, then, is whether Speech Graphics is future-proof. "In-game facial animation is commonly viewed as one of the critical pitfalls in the current generation," MacDonald explains. "With wooden faces and poor lip-sync being major complaints, this shortcoming will only become more pronounced in the next generation as surrounding game graphics come even more to life. Speech Graphics can have its greatest impact in such an environment: Faces will have more complex geometry, textures and deformers, which can take full advantage of the precise facial dynamics generated by our control systems."
MacDonald clearly understands the often cruel and volatile competitive landscape he and Speech Graphics are entering. With his vast experience in high-end game design, though, he should know how to navigate it, and under Speech Graphics' watch our CGI heroes should at least look like they know what they're talking about, too.
Tags: Post & VFX

RedShark 2020 @ All rights reserved.

Comments