3 minute read
Advertisement
iZotope’s RX application is the gold standard for repairing and enhancing audio. Erik Vlietinck put the latest version through its paces.
iZotope RX is one of those apps audio engineers already can’t live without, and the good news is that the new version of iZotope released only days ago has a number of features that will make dialogue and monologue editing a lot more efficient. For example, its Repair Assistant, which was already machine-learning driven in the past three versions, gains more intelligence and now proposes fixes in more areas.
There is one new feature of RX 10 Advanced that, in my opinion, will be a boon for anyone working in the broadcasting and film industries, and that’s the ability to turn on Text Navigation in dialogue editing. Text Navigation transcribes the spoken text of up to eight speakers, making them individually discernible using colour coded “lanes” for each recognised speaker right above the spectrogram and in a sidebar which includes a search field.
The search field allows you to find words so that, for example, you can quickly navigate to that part of a dialogue where de-essing is urgent, while leaving the other voice entries alone. It is the most spectacular new functionality of RX 10 Advanced, and it might open the possibility in future versions to allow you to export transcriptions to a text file.
If you’ve been anywhere near any text to voice apps recently you will be aware that the current state of the feature is not flawless. RX 10 isn’t 99.99% accurate — nor does it need to be, for that matter. The recognised text only serves to chop up large files using sound that resemble words. For example, in iZotope’s test file, a man and a woman are in the studio talking about home decoration in American English. By my reckoning the transcription engine misunderstood roughly around 10% of the dialogue.
For my own test file, I dictated a part from Wikipedia about Merlin, the wizard of Arthurian legend, in my best Belgian-accented English. The transcription engine misunderstood about 15% (again, my guesstimates).
Even with these inaccuracies, though, the essence of dividing up the file in chunks of textual content is kept intact. The search field works unexpectedly well. The secret lies in the use of a fuzzy search engine. You enter a couple of characters and the search field starts to fill up with possible words. In the example of “Merlin”, all the variations RX had listed turned up after the first three characters entered.
RX 10’s speaker identification isn’t 100% accurate yet, either. While I was alone in the room, RX insisted there were two of us, one identified as myself with a blue dot next to the ID and the other with a yellow dot next to the ID but with no lanes for the second one. With another file, where there were two people in the same room, RX thought there were three.
In both tests, except for the speaker, there was a lot of background noise ranging from bumps to devices turning on/off, stuff thrown on a desk, etc. That background noise resulted in lanes for the third speaker. Why the first test revealed a second speaker but no lanes, is a mystery (or a bug).
And yet, as with any apps that use automatic voice recognition, that doesn’t make this any less practical. With one click on a speaker’s coloured dot, you’re selecting everything they said and you can apply whatever improvement or fix on all of it at once.
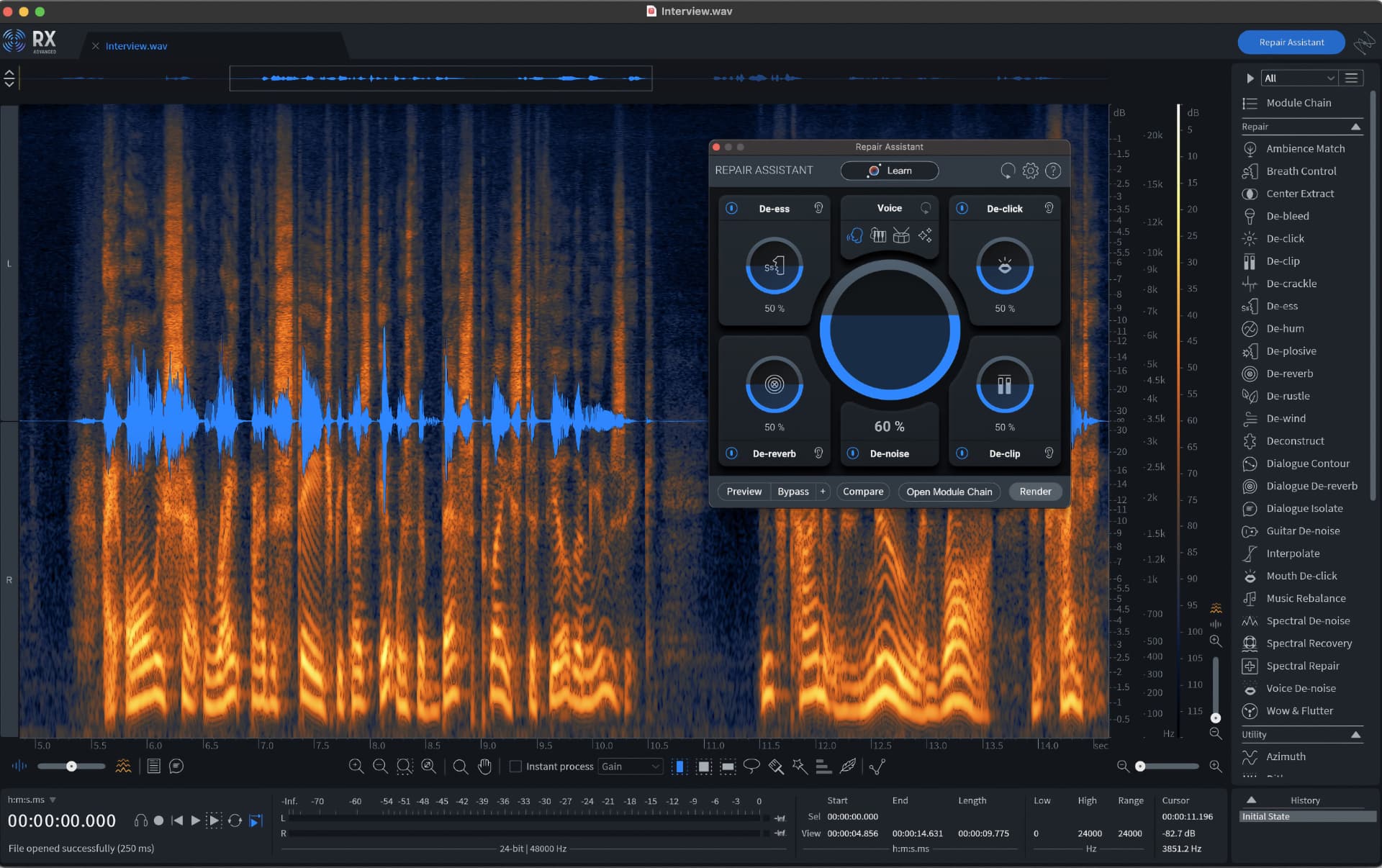
As much as the transcription capabilities are a boon for selecting and fixing speech, RX 10 lets you fix anything in a fraction of the time it took you with RX 7, RX 8 and even RX 9. To that effect the all-new Repair Assistant plug-in has been rebuilt from the ground up.
As with previous versions since RX 8, the Repair Assistant uses machine learning to automatically recognise specific problems and intelligently propose fixes that you can modify to taste (included with RX Elements, Standard, and Advanced) , but it does it using more modules at once and with better results than even RX 9 managed.
In my tests of the new Assistant, voice recordings with a serious de-essing problem were fixed and also improved in terms of dynamics, noise and reverb using one mouse click. In contrast to pure AI-driven repair and enhancement solutions on the market, however, you can change the decision of any of the six modules afterwards, right from within the Repair Assistant’s interface or by doing your own thing in the associated modules.
Less dramatic an improvement comes with the Dynamic Adaptive Mode in De-Hum. I always wished De-Hum would let me remove constant sounds that interfere with the desired signal regardless of changes in frequency — the new Adaptive mode does that now. It automatically eliminates complex noise that changes pitch, e.g. electromagnetic interference, without sacrificing quality (Standard and Advanced).
Perhaps least interesting from a film audio perspective, but still worth a mention, an upgraded Spectral Recovery improves upon the quality of the re-synthesized upper frequencies and can now add missing lower frequencies, too.
This is especially useful for recordings made on mobile phones or non-studio-grade recording equipment, but the resulting fuller sound will never be as good as when it were recorded using proper equipment. Still, for broadcast news this can make the difference between an unintelligible recording and one that is actually good enough to understand what interviewees are saying (Advanced only).
Finally, Selection Feathering has been improved and now works in both the time and the frequency domain. (Standard and Advanced)
RX 10 supports Apple silicon natively and the introductory pricing through October 11, 2022 for the new applications is as follows:
RX 10 Advanced: $799 USD (regularly $1,199 USD)
RX 10 Standard: $299 USD (regularly $399 USD)
RX 10 Elements: $99 USD (regularly $129 USD)
Tags: Audio

Written by Erik Vlietinck
Advertisement
Advertisement
Advertisement
Advertisement
Advertisement
RedShark is a multiplatform online publication for anyone with an interest in moving image technology and craft. With over 50 contributors worldwide, full-time developers, editorial, sales and marketing staff, it is the go-to site for informed opinion and know-how for the quickly changing video, film and content creation industries.
RedShark 2020 @ All rights reserved.

Comments