
5 minute read
Given the impact it’s already having on our daily lives, it’s worth possessing a working knowledge of how generative AI actually works. Rakesh Malik provides that and more.
No technology in human history has grown at the pace that AI is growing right now. It's gone from a nifty technology demo at nVidia's Game Technology Conference to the hottest and biggest technology on the planet in just a few years. It's gotten so big that nVidia is practically inviting AMD and Intel to take up its market in consumer gaming GPUs, yet its revenues are soaring.
Every major technology company on the planet is trying to get on board with the AI train, which is getting both bigger and faster at a pace that would have given Gordon Moore whiplash.
In spite of the dazzling progress and the enormous volume of press, it's still a very mysterious thing to pretty much anyone not in the field. So, how does it work? Let's start with neural networks.
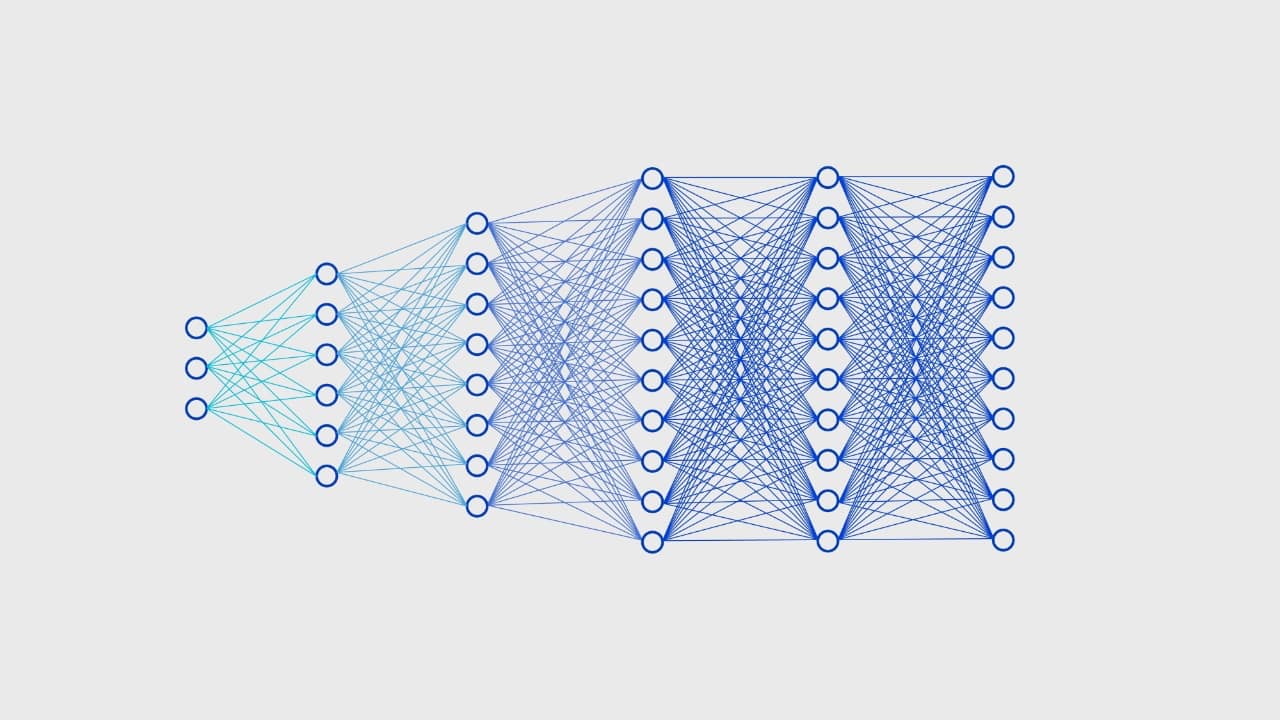
The basic concept of a neural network is pretty simple. It's a virtual network of simulated neurons called nodes, with one layer as the input and one layer as the output. In between are what are referred to as “hidden” layers. Each node in the input layer corresponds to one input parameter. There is no set number of nodes in any given layer, or to the number of hidden layers. The connections between network nodes are called “edges,” each of which has a weight.
Each node contains two functions. The first, called the non-linear function, collates the values the node receives on its input edges and outputs an activation value between zero and 1. The second function is the activation function, which determines whether or not the activation value is high enough to activate the node. If activated, the node will send its value to edge downstream node. The weights on the edges influence the value the next nodes receive, so an edge with a weight of zero is the same as no edge, while if the edge has a value of 1 it transmits the signal unchanged.
To activate a neural net, give it an input and read the output. Simple enough.
The neural network architecture, meaning how many layers of each type, how many connections there are between each layer, and the activation functions is designed around the task the network is going to be trained. The edge weights are preset usually with random values, and the dataset needs to be prepared around the task also. The training dataset includes input features and target values.
Give the neural network an input and propagate the signal to the output layer, also known as forward propagation. Calculate the correctness or lack thereof in the result and back-propagate the error through the network. Keep doing this for either a set number of iterations or until the network converges, which means that the edge weight changes are below a target threshold. Then use a validation dataset to test the network.

For an application such as a text-to-image synthesizer like MidJourney or Dall-E, there are multiple steps involved, all of them large.
The first step is to gather images with text descriptions into a dataset. Then train an AI such as a neural network on this data, so that it builds an association between the words describing the images and the content of the images, essentially “learning” what the images are. This part is very similar to teaching someone about apples by showing them several pictures of apples and describing those pictures until the person can recognize other pictures of apples, as well as the real thing.
The next step is the image synthesizer, trained with that dataset. One common method is a Generative Adversarial Network (GAN), which uses two neural networks working in competition, hence the term “adversarial.” One is called the “discriminator,” trained using real image data to differentiate real from fake images. The other is the generator, which takes random inputs and tries to generate images. As the training progresses, the generator gets better at tricking the discriminator, and the discriminator gets better at telling the difference between real and fake images.
Once trained, the generator can accept text and use it to synthesize images. After that techniques like Stable Diffusion can supplement the process to add resolution or remove noise.
These concepts can of course be translated to video as well. Take for example the AI object removal in DaVinci Resolve. The input is a video clip, and the output is a video clip plus a selection such as a telephone pole to remove. The AI needs to be trained to differentiate the pole from the environment. Then it needs to be trained to remove the pole from a video clip. For that to work convincingly, it also has to replace the space the pole occupied with image content synthesized from the surrounding image.
That of course isn't enough; it would make no sense to make a tool so specific that it can remove telephone poles, but not apples, branded coffee mugs, or wayward who sneaked past lockups from footage.
So the AI has to be able to recognize objects in general, even when the perspective changes throughout a shot due to cameramovements. For some objects like cats or wayward grips, their shapes change as they move even if the camera doesn't.
So for AI object removal, while it doesn't need a large language model, the AI needs to learn how to recognize objects, erase them cleanly, and synthesize realistic image data that remains consistent as the shape it's filling changes. All three are complex problems even by themselves, requiring training with large databases of image data, plus the hardware to run the neural nets on and then also to evaluate their results and back-propagate feedback through the networks.
The down side to this is that those trained models are static; there's no mechanism for evolving the AI with additional feedback and back-propagation, so updates are tied to new software versions. There is really no way yet to provide live feedback to the AI training models, but as datacenter AI systems grow in memory capacity and sheer power the training process will continue to accelerate.
On the flip side however, one of the great things about the same quirk is that while the training requires gigantic datasets already reaching into the terabyte range, once they're trained the neural net can be represented by some code to define the network topology and the non-linear and activation functions, plus a collection of matrices representing the edge weights and biases. That's why an AI trained on a massive datacenter for months can run in near realtime on a modest personal computer with comparatively tiny amounts of memory.

Adversarial training techniques are one example of unsupervised AI training. Vancouver-based Sanctuary AI is using physical models to train the AIs driving its humanoid robotic manipulators to perform delicate precision tasks like picking up chess pieces from a chess board and placing them in their new spot. On the surface that sounds simple, but there are a lot of muscles and joints and haptic feedback and proprioception that go into performing that seemingly simple task. Sanctuary is using physics to train the robots, essentially that same way that we learned to perform the same tasks.
AI applications like ChatGPT work in a similar fashion, except that instead of being trained on image data, they're trained on vast quantities of text. Evaluating the quality of that text can be a challenge, so the source text will have a huge impact on how effective the AI will be. Datasets like the contents of strictly moderated web sites like Stack Overflow are like gold for this purpose; an AI can absorb not only the content itself, but also the responses from other users which includes follow up questions, corrections, upvotes and downvotes, and even moderation.
Combine that with an AI trained in language processing, and it turns into a generative AI that can write working code. Add training with other forums like the open source content on Git, and now it can ingest and understand coding standards, comments from code reviewers catching bugs and suggesting optimizations as well as readability fixes, and it can incorporate that knowledge into the code that it generates, leading to cleaner, more readable, more efficient AND less buggy code than most humans would be able to write, especially in a first draft.
For those who would like an even deeper dive into more detail about these AI techniques and others, there are some excellent references available, including nVidia's website and for the more developer oriented, HuggingFace.co.
Tags: AI

RedShark 2020 @ All rights reserved.

Comments