
3 minute read
Replay: Camera forums are often full of discussion about bit-depth. But what is it, and why do we really need higher bit-depth?
Bit depth in cameras used to be simple. There was eight or ten and more was better, though a few cameras promoted 14-bit internal processing and raw stills could sometimes be even more. In 2020, it’s quite possible to find postproduction working in anything up to 32 bit, and lots of cameras offer various types of raw at almost any bit depth. What’s going on?
Binary mathematics is simple. A single bit can encode two levels: off or on. Add another bit, and we can have all the previous levels with the new bit off, and all the previous levels again with the new bit on. That’s why adding a bit always doubles the number of levels we can represent. More levels means more, and therefore finer, graduations of brightness in an image.
Mathematically, the number of levels is always equal to two raised to the power of the number of bits. On a scientific calculator, hit 2, xy, 8, =, and get the answer 256 for the number of levels in an 8-bit image. This means that adding bits is actually a pretty efficient way to improve an image: 10 bit pictures only take up 25% more storage space than 8 bit pictures, but they have four times the number of levels.
16 bits are even more impressive, capable of representing 65,536 levels. The number for 32 bits is some enormous telephone numbers. That prompts the question, if we can really see that number of gradations of brightness in an image? The answer is a simple no. We’re not doing this simply because more is more. The reason we see these high-precision bit depths is because of a big complicating factor: brightness encoding.
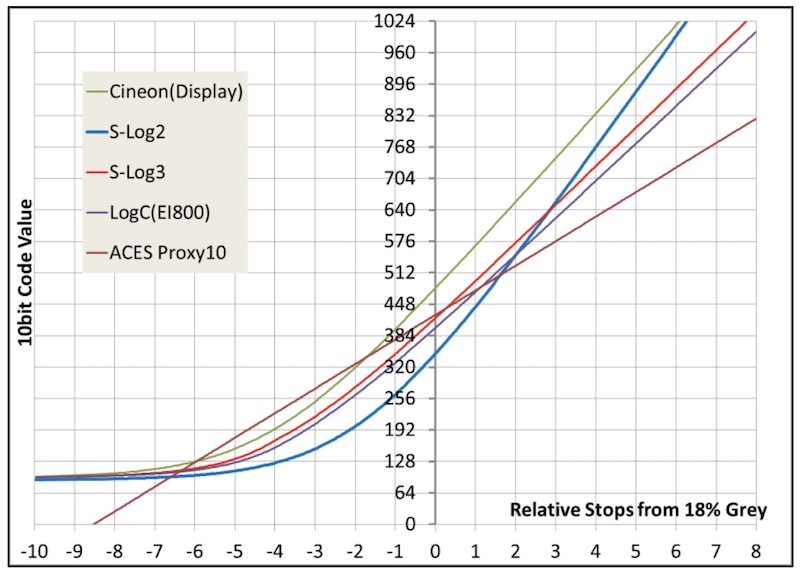
We’ve touched this before, but to recap, the numbers in a file do not usually represent the number of photons that hit the sensor. That’d be a linear light recording. Often logarithmic encoding is used, which means tweaking things so that every numeric increase looks like roughly the same amount of increase in actual brightness. The two aren’t the same simply because of the way human eyes behave. Log encoding works really well for on-camera recording because it means that the bits we have are used most effectively.
If we don’t use gamma encoding, we would need an absolutely huge number of bits to represent a big enough range of brightness, which takes up more space. People use 16 (or more) bits because they don’t want to use any sort of clever brightness encoding. It’s more common in post production files than camera recording. In post, we might have lots of different cameras to put on the same timeline, and we might need to convert all of them into a simple internal format so they can be graded together. On a big post production workstation, there’s more storage available, and we’d probably rather not keep converting material in and out of various bit depths to work on it.
Some cameras do record high bit depths, however; Blackmagic Raw is a 12-bit format that uses a hybrid approach with some degree of clever brightness encoding and a medium-high bit depth. Generally cameras like these will be using compression, as Blackmagic Raw, ProRes Raw and most of the other on-camera raw formats do, going all the way back to CineForm. CinemaDNG doesn’t use compression (at least not lossy compression) and supports anywhere from 8 to 32 bits, but as a result it absolutely chews through storage.
There are a few subtleties to how bits work. Anyone who uses ACES will encounter terms like “16-bit half float,” which refers to floating point numbers. This is a way to represent fractional numbers (11.7 as opposed to 12) which basic binary numbers don’t do. There are a few variations, but the main way that’s done is to separate the available bits into two groups. The first one contains the digits of the number, and the second contains the number of places to move the decimal point. If the first group contains 117 and the second contains 1, the result is 11.7. That doesn’t change precision, specifically – we can define black as 0 and white as 100, or we can define black as 0 and white as 1.00 with much the same results. There are some reasons that floating point numbers can work better specifically when we’re representing image data, but they get a bit complicated.
We’ll look into that another time, perhaps, but in the meantime let’s be clear that as far as bitcount goes, more is better, but the difference is as much to do with how we use those numbers as how many numbers we have.
Tags: Production Editor

RedShark 2020 @ All rights reserved.

Comments