2 minute read

Japan-based Fujitsu Laboratories has revealed a video compression technology that uses artificial intelligence (AI) to dramatically reduce the file size of content compared to existing video codecs.
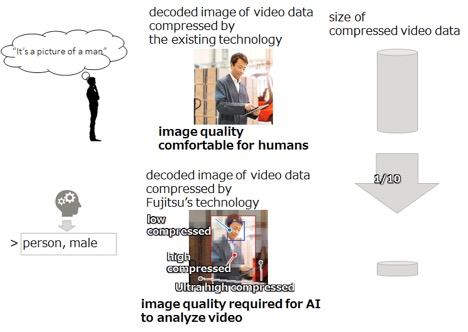
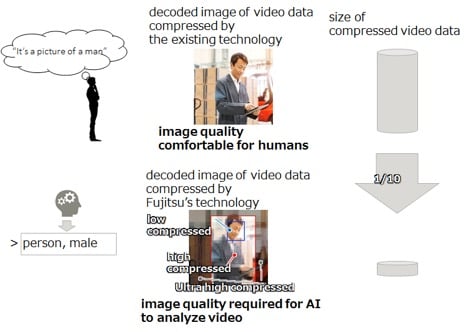
How much so? When applied to 4K video content, Fujitsu said, “data size could be reduced to 1/10th the data size of conventional compression technology without a deterioration in recognition accuracy.”
In developing this new compression technology, Fujitsu focused on an important divergence in the way in which AI and humans recognize images. Namely, AI and humans tend to differ in the areas of the image that are emphasized as important for judgment when recognizing people, animals, or objects in video data. For example, humans tend to focus on faces in an image. Conventional codecs apply high fidelity to such areas, but with AI assistance for image restoration, low fidelity can be used in such areas. Fujitsu’s technology automatically analyzes the areas that AI values to compress data to the minimum size that AI can recognize.
According to the researchers at Fujitsu Labs, their AI-based method appears to be a pre-encoding analysis that is used as an input to more conventional encoding algorithms like HEVC. This analysis uses machine-learning to evaluate certain classes of objects. Such machine learning typically uses machines to look at high- and low-resolution images of target objects to better understand the minimum features needed to restore a high-fidelity image from a low resolution source.
The Fujitsu analysis is done on a frame-by-frame basis. Motion analysis is done by the conventional encoding software.
So far, Fujitsu has only evaluated the process for reducing file size and has not evaluated how it might impact image streaming data rates. For the file size reduction result, we asked for more details on this test. According to the researchers, they compared their pre-processor plus HEVC encode to a standard HEVC encode to obtain the 1/10th file size reduction. However, they were not able to provide further details such as the 4K frame rate, color sub-sampling or encoding profile used.
Encoding was done using NVEnc from NVIDIA with decoding done in existing hardware or software solution. Such encoding does not appear to be possible in real time, but the researchers are evaluating encoding “under various conditions”, we were told.
The researchers also claim there is no loss of image quality when using their algorithm, so we asked how they assessed visual quality (PSNR, SSIM, VMAF)? “Using recognition accuracy as an index, we compared (not degrading) the recognition accuracy rates of recognition engines,” said the Lab. “The effect of image quality degradation specific to compression on recognition accuracy is analyzed for each area. The compression ratio that does not affect recognition accuracy is automatically estimated based on the AI recognition results.”
The idea of using an encoder pre-processor is not new nor is the use of AI to aid in encoding. For example, the P+ codec from V-Nova is billed as a pre-processor that can be used in conjunction with other codecs to reduce streaming bit rates. Plus, companies like Sharp and Samsung are already developing new streaming technology that uses AI to reduce bit rates. What is unclear is if these efforts are also a pre-processor type step or if these are new codec approaches.
Fujitsu Labs has more work to do before a commercial product can be offered, but they think that can happen by the end of 2020. “We are building an internal business structure to offer it as an ICT platform technology. Customers might see the platform middleware,” stated the Lab.
Tags: Technology

RedShark 2020 @ All rights reserved.
Comments