4 minute read
 Video Processing, Part 3
Video Processing, Part 3
In the third part of our four part series on video processing and standards conversion, Phil Rhodes explains why frame rate conversions and temporal remapping is such arduous tasks.
In the previous instalment of our series on video image processing and standards conversion, we discussed scaling, which is such a common requirement that examples seem redundant. What's less well known is that good scaling is surprisingly hard work, especially if it must be done in real-time to video data that may contain a dozen megapixels per frame, and several dozen frames per second.
Scaling in two dimensions, however, pales in comparison to the problems we face when trying to re-time video, to scale it in the temporal dimension. Even in the trivial case of reducing the frame rate by (for instance) half, to do a technically correct job we must apply additional motion blur, to normalise the apparent motion rendering of a fifty-percent exposure duty cycle - the equivalent of a 180-degree shutter in film, or 1/60th of a second exposure in 30fps video. While the motion blur issue can often be ignored in simple cases like this, more common requirements, such as conversion of 25fps PAL-region video to look good when distributed at 29.97fps, aren't so easy.
Perhaps the earliest solution to this sort of problem is the 3:2 pull-down applied to film footage, which used the alternating lines of interlaced video to blend frames without needing any advanced electronics (which didn't really exist when the technique was developed) and continues to make life easy for DVD players to this day. However, the appearance of 24fps film, when transferred to nearly-30fps video in this way, is so identifiable that it's used to this day in order that people in NTSC regions get films that look as expected; most modern standards conversion needs to be a lot more invisible than that.
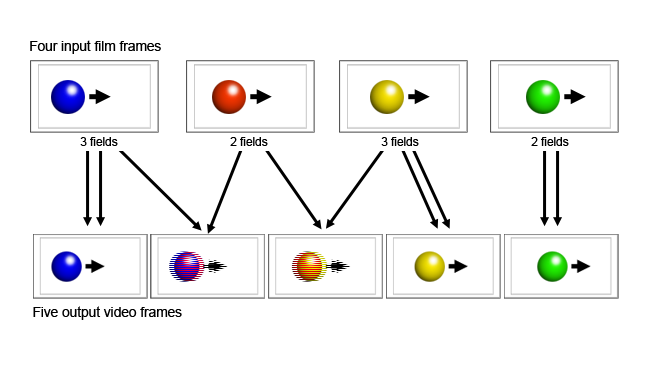 [Fig. 1: 3:2 pulldown]
[Fig. 1: 3:2 pulldown]
The solution to both frame rate conversion and motion blur actually comes from the same ability: the generation of new frames based on pre-existing ones. Motion blur is often simulated by averaging a number of newly-generated frames, so the problems we need to solve are more or less the same either way. It hasn't been possible to do this very convincingly for very long, at least compared to scaling; the key techniques for making up new frames, called motion estimation or optical flow, rely on computers to do an enormous amount of heavy lifting.
The genesis of motion estimation, which at its core is a task of tracking where an object from one frame has moved to in the next, comes from things like military target tracking via video compression. Our ability to place computer-generated objects in scenes where the camera is in motion relies on the same ability of a computer to take an area of an image and match it to a similar area in another image, with unerring accuracy. Needless to say, given the fact that a video frame is a two-dimensional representation of (usually) a three-dimensional scene, and because cameras produce noisy images, it isn't something that can ever be a perfect solution. At its most fundamental level, then, most of the development that's happened in the field is dedicated to finding more efficient ways for a computer to take a chunk of one image and find where that chunk has moved to in another.
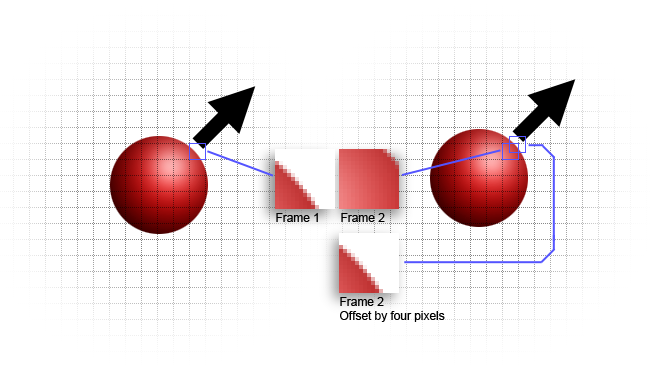 [Fig. 2: Motion compensation]
[Fig. 2: Motion compensation]
It's worth a brief digression at this point to discuss the relevance of this to video compression, where related techniques are called motion compensation. Estimating and recording the position and movement of small areas of the image (called macroblocks and often eight pixels square) can provide either new image data or a rough idea, leaving the codec to compress only the difference between that and the ideal image. This has been a key part of video compression since the earliest days of codecs designed to allow video conferencing via the telephone network. At that time, the limitations were not only of bandwidth but also of computing power and, as such, the mathematics are well developed for efficiency.
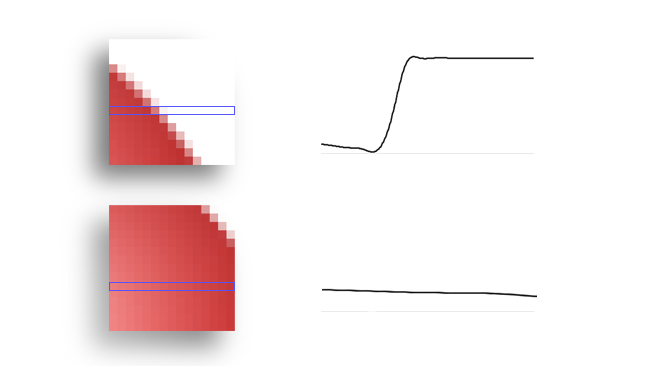
The two prototypical techniques for actually finding out where a chunk of image has gone are block matching and phase correlation. Block matching is a simpler approach, in which the pixel values of the reference image block are subtracted from those of a target block. If the target block and the reference block are identical, the result will be zero, although in reality, noise will mean that the best matching block will be that with the smallest result. In this example, the subtracted output is multiplied (brightened) four times to make the difference more visible.

[Fig. 3: Block matching]
This is a somewhat brute-force option, inasmuch as every possible target block near the reference block must be individually searched and an enormous number of calculations done. Phase correlation, on the other hand, works in the frequency domain, which is a linguistically adventurous way of saying that it uses some of the same mathematics as still image compression to recognise patterns, as opposed to relying on simple pixel values, and can be rather faster. In the example below, we consider a single row of pixels from a 16-pixel-square macroblock and the graph formed by the values, which can be evaluated for a match with another graph from another macroblock. This is the very much simplified basis of a technique by which blocks can be quickly evaluated for a match.
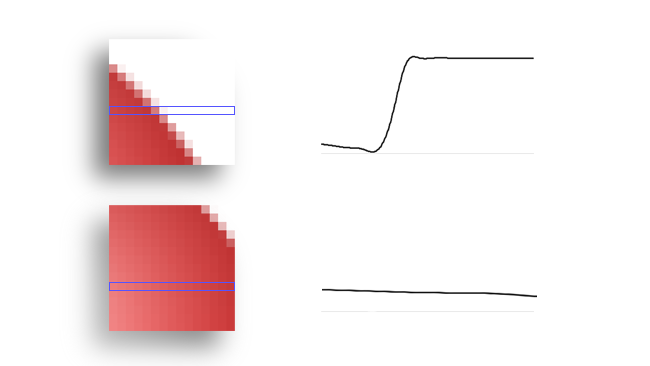 [Fig. 4: Phase correlation]
[Fig. 4: Phase correlation]
Add to this the extra calculations required to achieve accuracy smaller than a pixel, which is required for the very best results, and it's pretty clear that the sheer density of calculations associated with motion estimation is absolutely enormous. Only with recent technology is there any hope of doing it given a reasonable amount of rendering time, let alone in real-time.
Once a piece of software has determined the motion in an image, it becomes possible to slide groups of pixels around to produce a convincing estimate of a new frame, representing a point in time where none previously existed. Anyone who's used the "remap time" feature in After Effects, with the high quality interpolation switched on, has seen optical flow in action. Problems are generally caused either by noise or by repetitive elements being incorrectly matched, which might have meant that those difficult star fields in Star Trek might still have been slightly tricky. Objects moving fast enough that they pass outside the range over which the algorithm searches for similar blocks of image between frames can cause problems, and motion blur can confuse things. Even so, the results available from optical flow-based frame rate interpolation completely eclipse older technologies.
Tags: Technology

RedShark 2020 @ All rights reserved.

Comments