
3 minute read

 Power supply circuitry on a modern graphics card.
Power supply circuitry on a modern graphics card.
In a new two-parter on GPUs, Phil Rhodes explores why the GPU has not yet made the CPU obsolete, and the times in which the sheer performance of a modern GPU gives you the best computing option available..
The explosive growth of performance in graphics cards and,particularly, recent excitement over announcements from AMD about its Radeon line, serves to highlight the fact that the CPU is no longer the key indicator of performance for a modern workstation. Is a desktop computer becoming nothing more than a life support system for a graphics card?
Well, no, it isn't. With old yet potent Xeon E5-2670 CPUs being pulled out of data centres and thrown on eBay for under £100, it's never been easier or cheaper to put together a 16-core workstation. The fact that CPU horsepower has improved only a few percent generation-on-generation in the last half-dozen years means that these older chips, despite being rather more power hungry (thus their disfavour in server farms), are only slightly less powerful than more recent products. Clock speeds have hardly moved and improvements in efficiency achieved a few percent at best and can be sensitive to the exact type of work.
Xeons in particular also tend to have an enormous amount of cache memory, the scratchpad used by the CPU to keep data available for quick access. 5MB of level-three cache per core on the 2670 ensures fewer cache misses, where the CPU can't find the information it needs in its onboard memory and has to go to the much slower main memory for data. Bigger cache size is a way to increase the average number of instructions executed per clock cycle, without wasting time waiting for main memory. So, even if there are modest clock rate increases, more recent desktop-oriented CPUs, which suffer smaller caches, may struggle to keep up with the big iron of a few years ago.
 Modern graphics cards generally include a large amount of high-speed memory for the private use of the GPU itself.
Modern graphics cards generally include a large amount of high-speed memory for the private use of the GPU itself.
So, we can get very fast CPUs for not much money. Even so, does even the best CPU have the same heavy-lifting potential as a modern GPU? Well, they do very different things, but on many levels, not even slightly.
It's tricky to come up with meaningful comparisons, because core count doesn't tell us much. A hyper-threaded, eight-core Xeon can look like it's doing sixteen things at once. A modern GPU might be able to do 2500 things at once. Now, each of those things is rather simpler than the things a CPU can manage. Most current CPUs support hundreds and hundreds of advanced and very capable instructions, from simple addition up to things with names like 'Convert with Truncation Scalar Single-Precision Floating-Point Value to D-word Integer'. GPU cores are rather more straightforward. It's difficult to compare the types and numbers of instructions available, as many GPUs implement things differently from each other, but each core is generally much, much simpler than a CPU core.
 One of the enormous logic emulators used by Nvidia in the development of GPUs.
One of the enormous logic emulators used by Nvidia in the development of GPUs.
This is to be expected; a single eight-core CPU might draw over 100W of power, whereas a graphics card might average a couple of hundred when rendering the visuals for a demanding game (like CPUs, GPUs are improving power consumption versus performance, generation-on-generation). The cores are simpler, yes, but that's less than twice the power for more than three hundred times the number of them.
The real key, though, is that those thousands of cores on the GPU are generally set up to do only one thing, repeatedly, to a huge set of data. The eight cores on the Xeon can do eight completely different things. The GPU is at its most effective when doing the same task to a lot of things at once and it's therefore fortunate that so many modern problems (rendering polygons or filters on video frames) are very repetitive. For those specific tasks where a lot of things can be done at once, the huge number of cores, despite their relative simplicity and lower speed, is absolutely overwhelming. This is what parallel processing refers to: the idea of doing lots and lots (and lots) of things at once.
The computer science terminology for this is vector processing or, perhaps more accurately, SIMD, which stands for 'single instruction, multiple data'. We're doing the same maths repetitively to lots of numbers. Modern CPUs do have SIMD instructions where the same operation can be performed on perhaps four things at once per core, but doing four things at once pales in significance compared to the thousands of simultaneous operations possible on a GPU. SSE and related techniques help and are great, but it isn't parallel processing on anything like the scale of a GPU.
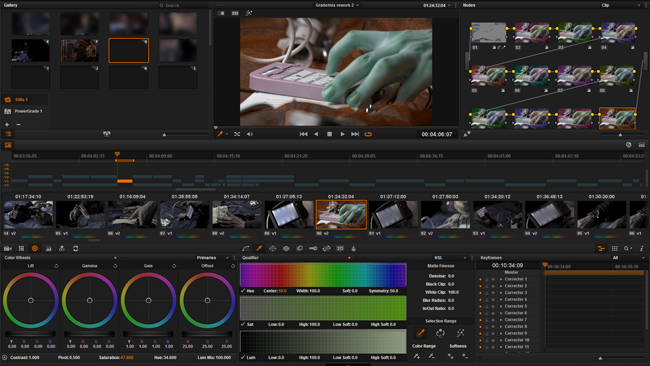 Hue and saturation changes, along with blur, are hard work.
Hue and saturation changes, along with blur, are hard work.
Such a repetitive task, however, is ideally suited to GPU computing.
The application of this in workstations stems from the GPU's history as a device for rendering 3D graphics. The visuals of modern games (and modern simulations of all kinds) are based on objects made out of triangles; there are thousands of triangles, each of which has to be drawn on the 2D display based on its position in 3D space. That's three points to calculate for each triangle and then calculations have to be done to work out the lighting and surface texture of that triangle. Some of those calculations involve consideration of each pixel on the display individually, which means that, for an HD display at 60 frames per second (as is preferred in computer games), something like 120 million pixels per second must be considered, perhaps more than once. It's very, very repetitive work. These huge numbers are achievable because they're handled by consumer products that attract huge research and development funding. HD colour grading on an affordable workstation would not have happened without video games.
 The huge market of computer games made the development of modern GPUs possible.
The huge market of computer games made the development of modern GPUs possible.
Tags: Technology

RedShark 2020 @ All rights reserved.

Comments